文件系统是操作系统用于组织和管理存储设备或分区上的文件的方法和数据结构。操作系统中负责管理和存储文件信息的软件组织称为文件管理系统,简称文件系统。
下图中是Linux上常见的本地文件系统,Windows常用的文件系统有NTFS,当然随着技术发展,各种基于网络的分布式文件系统,也是层出不穷,比如:NFS、CIFS(windows),还有一类集群式的分布式文件系统,比如:Lustre、Ceph,这类文件系统在数据洪流、万物智联的在今天应用更加广泛。

文件系统是操作系统用于组织和管理存储设备或分区上的文件的方法和数据结构。操作系统中负责管理和存储文件信息的软件组织称为文件管理系统,简称文件系统。
下图中是Linux上常见的本地文件系统,Windows常用的文件系统有NTFS,当然随着技术发展,各种基于网络的分布式文件系统,也是层出不穷,比如:NFS、CIFS(windows),还有一类集群式的分布式文件系统,比如:Lustre、Ceph,这类文件系统在数据洪流、万物智联的在今天应用更加广泛。
ext2使用page页面缓存来完成对文件的读写。这些页面的管理是通过inode的字段i_mapping来完成,也就是地址空间。所以在创建inode时,要指定i_mapping的操作表a_ops,帮助地址空间完成页面操作。
参考:014 Linux文件系统数据结构详解:地址空间struct address_space
地址空间操作表a_ops中,需要指定读page、写page等多种页面操作的函数指针,但是具体的块操作(读取、写入)、buffer操作、VM页面操作,其实文件系统不用太关注,因为Linux内核提供了大量公共函数(参考:buffer.c和mpage.c),文件系统可以直接调用完成读取和写入。但是,文件系统需要提供块的映射方法,帮助完成文件系统逻辑块号(就是在文件中的偏移量)到实际块设备块号映射,最后填充到buffer_head中。
// inode.c
const struct address_space_operations ext2_aops = {
.set_page_dirty = __set_page_dirty_buffers,
.readpage = ext2_readpage,
.readahead = ext2_readahead,
.writepage = ext2_writepage,
.write_begin = ext2_write_begin,
.write_end = ext2_write_end,
.bmap = ext2_bmap,
.direct_IO = ext2_direct_IO,
.writepages = ext2_writepages,
.migratepage = buffer_migrate_page,
.is_partially_uptodate = block_is_partially_uptodate,
.error_remove_page = generic_error_remove_page,
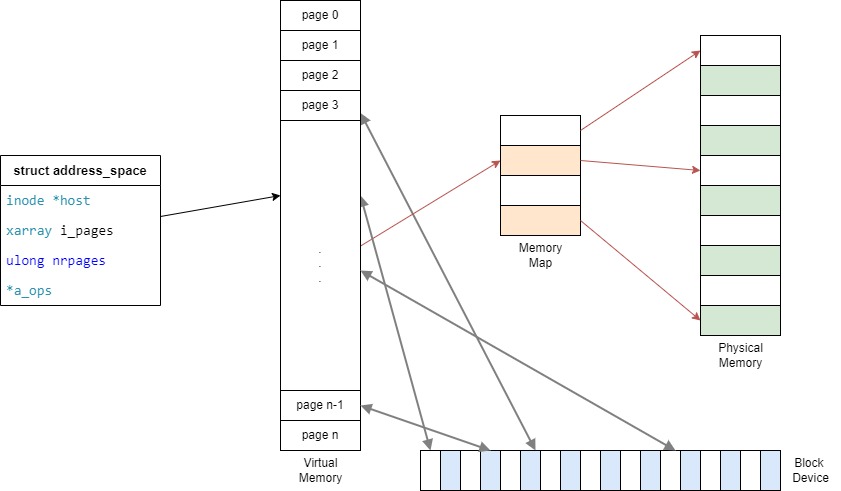
};什么是地址空间address_space?是Linux内核提供的一种数据结构,通过该数据结构可以管理离散到各设备上的数据映射到内存的page缓存页面。
听起来很晦涩,其实地址空间就是一个中间层,内核把周边离散的设备组织起来,然后映射到page缓存页面,内核子系统通过地址空间,就可以操作这些page缓存页面,进而达到操作周边设备的目的。
所以page就是内核管理的虚拟内存空间,它是真实物理设备的在内存上的映射,通过操作page页面,就可以完成对具体物理设备操作,这样做的好处是:
举例说明:一个文件的数据存储在块设备上,内核将块设备映射到缓存页面page,VFS通过地址空间就可以操作缓存页面page,完成文件的读取和写入。
在Linux文件系统中,inode就代表一个磁盘上的文件,所有磁盘文件的操作,最终都落到inode上去处理,inode的生命周期管理非常重要。但是inode的创建、写入、读取和删除,通常不是独立的流程,它是裹挟在其它的大IO流程中,比如创建文件。但是在其它流程中,inode的处理的介绍几乎是一笔带过,所以,有必要针对inode管理,总结一篇详实的材料。本文还是以ext2文件系统为例,来讲述inode生命周期的管理。
首先,你要知道inode管理的操作函数,都是在超级块结构体里声明,因为inode自己的操作表,都是和文件操作相关。好,我们一起来看一下:
// super.c
static const struct super_operations ext2_sops = {
.alloc_inode = ext2_alloc_inode,
.free_inode = ext2_free_in_core_inode,
.write_inode = ext2_write_inode,
.evict_inode = ext2_evict_inode,
.put_super = ext2_put_super,
.sync_fs = ext2_sync_fs,
.freeze_fs = ext2_freeze,
.unfreeze_fs = ext2_unfreeze,
.statfs = ext2_statfs,
.remount_fs = ext2_remount,
.show_options = ext2_show_options,
};上一篇说到ext2文件系统删除文件是逻辑删除,对应文件系统的unlink操作,其实就是解除磁盘目录项与inode关系,同时删除目录项(也是逻辑删除,与前一项合并)。那么,同样删除目录跟删除文件类似,ext2也是做了一次unlink操作。详细的删除目录流程如下:

前面几篇博客讲了创建文件、创建目录、查找文件,接下来说一下ext2文件系统是如何删除文件,ext2文件系统删除文件,并没有在物理设备上擦除文件,只是做了一个unlink操作,所谓的逻辑删除。unlink的具体实现,就是解除目录项与inode关系,这样目录项就不会关联到inode,就无法查找到文件,达到了删除的目的。unlink的具体的流程如下:

在打开文件、列举文件或者stat()操作时,用户端给的是文件路径信息,内核文件系统需要根据路径,查找到对应的inode,这样才能生成file对象,才能进行后续的读写等操作。所以,文件查找是一个基础能力,是其他文件操作的前置条件。
所谓查找文件,就是找到路径对应的dentry项,通过dentry项找到对应inode信息,有了inode才能对文件进行其他操作。文件查找时,优先在dcache缓存中查找,如果没有找到,需要到磁盘上进行遍历。
在dcache中查找,是VFS层面的基本动作,dcache如果没有找到,VFS就会调用具体文件系统的lookup()函数,到磁盘上进行遍历。以ext2文件系统为例,lookup具体流程如下:

前一篇介绍了在目录下创建文件,我接下来们继续ext2主IO流程:创建目录。不论是创建文件还是创建目录,都是基于父目录,两者有很多相似之处,都要新建inode和目录项,然后建立inode与dentry的关系。但是创建目录操作,在写入目录项时,要多写两个目录项.(当前目录)和..(上层目录),详细流程如下:

创建文件是文件系统的基本操作,之前在介绍Linux文件系统VFS时,说过创建文件会调用inode操作表中的create()函数,那create函数具体应该如何实现呢?
文件系统在创建文件时,VFS会调用父目录目录的create()函数,在这个函数中要完成具体的文件创建,以ext2文件系统为例,ext2注册的创建文件的函数指针是ext2_create,在ext2文件系统创建文件,一般包括以下几个步骤:

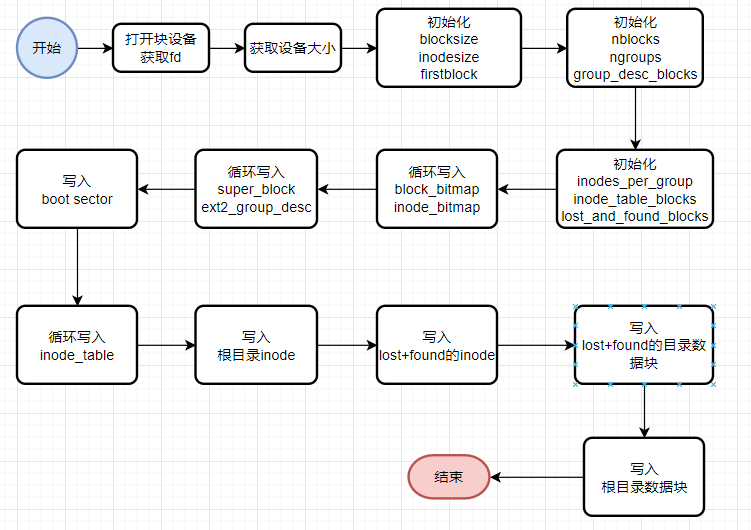
要使用ext2文件系统,要先在设备上创建文件系统,也就是对设备进行格式化。常见的格式化工具有e2fsprog的mkefs,还有busybox的mkfs.ext2。接下来就以busybox的工具为例,介绍具体的格式化流程。
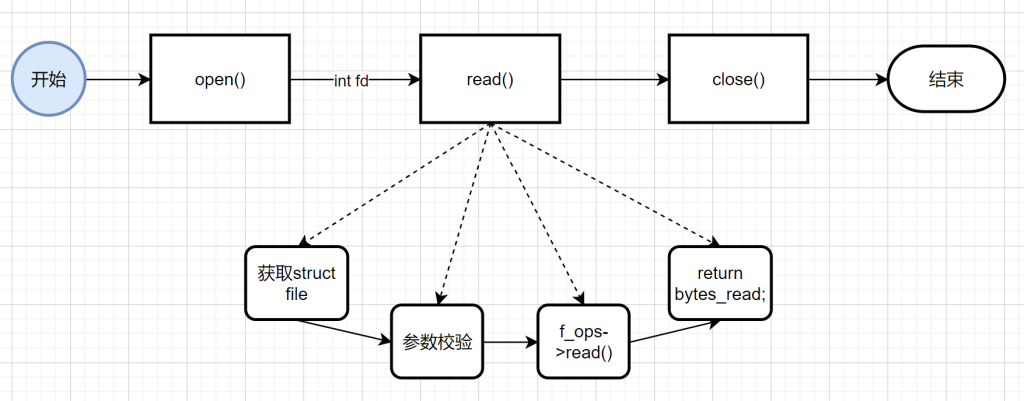
上一篇介博客绍了文件写过程write(),接下来看一下读过程read()。在写过程中,根据打开文件的文件描述符,获取文件对象指针file*,然后调用操作表中的write()函数或write_iter()函数,完成写操作file->ops->write()。读过程与写过程类似,最终调用的是read()或read_iter()函数。