前面介绍了文件系统的各种结构体,那么一次打开文件过程,需要和哪些结构体产生联系呢?要解决上面提出的问题,就要先搞清楚,函数是调用流程是怎样的,调用过程中串联了哪些数据结构,说起来也就是回答如下几个疑问:
- 打开文件的内核入口在哪里?
- 打开文件时,如何知道当前属于哪个文件系统呢?
- 如果文件已存在,那又如何获取目录项dentry和索引节点inode呢?
- 文件对象file是怎么构造的?
- 文件描述符是怎么产生的,又是如何跟file对象关联起来?
一、代码示例
以下代码示例,描述了一个打开文件、写文件、关闭文件的过程。为了避开libc的影响,没有使用C语言的fopen()打开文件,而是在代码中直接使用了系统调用open()。代码编译后在用户态运行,通过系统调用会进入内核态。
简单说明一下,本文不会介绍系统调用表如何生成,会直接从内核函数开始,关于系统调用表,在其他文章中会详细介绍。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <fcntl.h>
struct student
{
char name[33];
int age;
double score;
} stu = {"King Garry", 24, 93.5};
int main()
{
int fd;
char fname[] = "/fout.txt";
char cwd[129];
char stus[64] = { 0 };
if(getcwd(cwd, sizeof(cwd)) != NULL) {
printf("Curr dir: %s\n", cwd);
} else {
perror("Err info: ");
}
strcat(cwd, fname);
fd = open(cwd, O_CREAT | O_WRONLY, 0755);
if (fd == -1) {
printf("Open file [%s] fail!\n", cwd);
perror("Err info: ");
}
sprintf(stus, "%s-%d-%.2f", stu.name, stu.age, stu.score);
write(fd, stus, strlen(stus));
close(fd);
printf("Finish\n");
return 0;
}open()函数原型:
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
二、打开文件
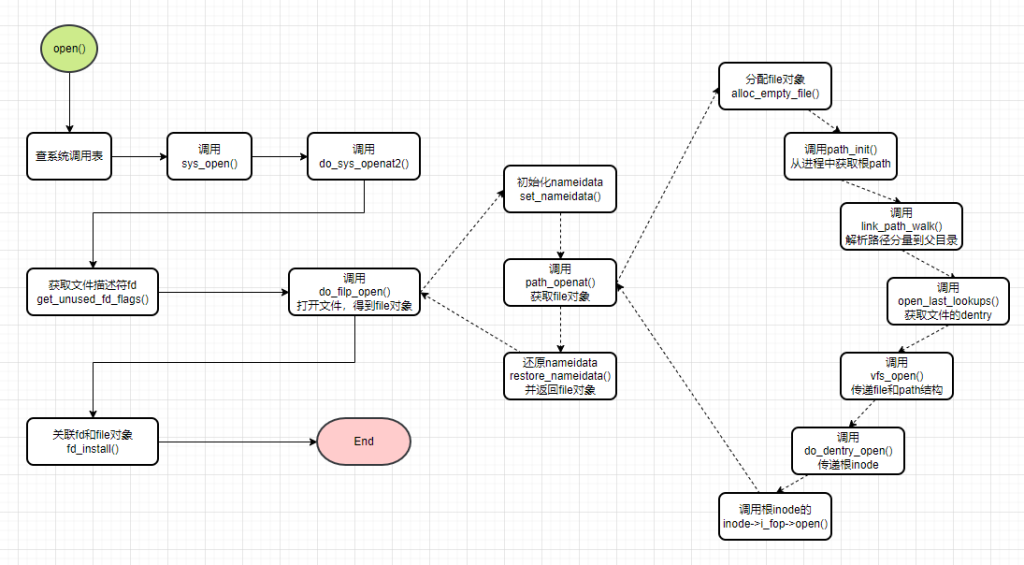
打开文件的详细流程图,参考文章开头的图片。
1.进入内核入口
在用户态调用open()函数时,会进入内核如下代码,执行do_sys_open()函数。参数有filename、flags、mode这些都是用户态传入的,另外还多了一个参数AT_FDCWD,本文先不做介绍。
紧接着在调用do_sys_openat2()函数之前,调用了build_open_how()函数,将flags和mode两个参数,整合成了struct open_how类型。内核入口就这么多,我们继续往下看。
// fs/open.c
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, umode_t, mode)
{
if (force_o_largefile())
flags |= O_LARGEFILE;
return do_sys_open(AT_FDCWD, filename, flags, mode);
}
long do_sys_open(int dfd, const char __user *filename, int flags, umode_t mode)
{
struct open_how how = build_open_how(flags, mode);
return do_sys_openat2(dfd, filename, &how);
}
2.获取文件描述符
接下来在do_sys_openat2()函数中,又将struct open_how类型,转换成struct open_flags类型,具体做了什么,这里不做详细介绍。
static long do_sys_openat2(int dfd, const char __user *filename,
struct open_how *how)
{
struct open_flags op;
int fd = build_open_flags(how, &op);
struct filename *tmp;
if (fd)
return fd;
tmp = getname(filename);
if (IS_ERR(tmp))
return PTR_ERR(tmp);
fd = get_unused_fd_flags(how->flags);
if (fd >= 0) {
struct file *f = do_filp_open(dfd, tmp, &op);
if (IS_ERR(f)) {
put_unused_fd(fd);
fd = PTR_ERR(f);
} else {
fsnotify_open(f);
fd_install(fd, f);
}
}
putname(tmp);
return fd;
}下面列出这段代码最重要的几个函数是:
1)do_filp_open():执行打开文件,获取文件对象指针file*,下面会详细讲解,这里不做介绍
2)get_unused_fd_flags():获取文件描述符fd:
文件描述符是通过alloc_fd()函数分配,这个函数里根据struct fdtable结构体中unsigned long *full_fds_bits; 这个字段的来生成fd。
full_fds_bits是一个long型数组,每个元素二进制是32位或64位(取决于系统类型),在内核当中也叫位图Bitmap。每个进程都有自己的file对象数组,对应就有一个文件描述符fd位图。假设full_fds_bits是64行,每行64个位,这样就有4096个fd可用,也就是说每个文件打开的文件数(使用ulimit -n xxx可修改)。
在分配fd时,从full_fds_bits数组当中逐行检查,寻找这一行所有位当中,是否有哪一位是0,有的话把对应的位置作为fd,然后标志成1,表示busy。如果当前行的位全是1,那就继续到下一行寻找,直到直到找到为止。实现函数find_next_zero_bit()。
/*
* allocate a file descriptor, mark it busy.
*/
static int alloc_fd(unsigned start, unsigned end, unsigned flags)
{
struct files_struct *files = current->files;
unsigned int fd;
int error;
struct fdtable *fdt;
spin_lock(&files->file_lock);
repeat:
fdt = files_fdtable(files);
fd = start;
if (fd < files->next_fd)
fd = files->next_fd;
if (fd < fdt->max_fds)
fd = find_next_fd(fdt, fd);
......
}
/**
* find_next_zero_bit - find the next cleared bit in a memory region
* @addr: The address to base the search on
* @offset: The bitnumber to start searching at
* @size: The bitmap size in bits
*
* Returns the bit number of the next zero bit
* If no bits are zero, returns @size.
*/
static inline
unsigned long find_next_zero_bit(const unsigned long *addr, unsigned long size,
unsigned long offset)
{
if (small_const_nbits(size)) {
unsigned long val;
if (unlikely(offset >= size))
return size;
val = *addr | ~GENMASK(size - 1, offset);
return val == ~0UL ? size : ffz(val);
}
return _find_next_bit(addr, NULL, size, offset, ~0UL, 0);
}3)fd_install():打开文件后安装fd和file*,也就是关联fd和文件对象指针,其实最关键操作就是rcu_assign_pointer(fdt->fd[fd], file),将文件对象file赋值给fd下标的元素。
void fd_install(unsigned int fd, struct file *file)
{
struct files_struct *files = current->files;
struct fdtable *fdt;
rcu_read_lock_sched();
if (unlikely(files->resize_in_progress)) {
rcu_read_unlock_sched();
spin_lock(&files->file_lock);
fdt = files_fdtable(files);
BUG_ON(fdt->fd[fd] != NULL);
rcu_assign_pointer(fdt->fd[fd], file);
spin_unlock(&files->file_lock);
return;
}
/* coupled with smp_wmb() in expand_fdtable() */
smp_rmb();
fdt = rcu_dereference_sched(files->fdt);
BUG_ON(fdt->fd[fd] != NULL);
rcu_assign_pointer(fdt->fd[fd], file);
rcu_read_unlock_sched();
}3.路径解析获取文件dentry***
打开文件过程非常重要一步,就是解析文件路径分量,用户态传递的文件路径可能是绝对的,也可能是相对的,解析路径分量目的就是识别完整路径,最终获取文件的父目录dentry,整个过程一共分为如下4个步骤:
- 构造file文件对象结构体(函数:alloc_empty_file()),后续会填充属性信息
- 构造nameidata结构体,用于后续的路径分量解析时,记录过程数据
- path初始化,从当前的进程的task_struct结构里,获取工作目录的path结构(主要使用dentry)
- 然后逐级路径分量解析,直到当前文件的父目录,获取父目录的dentry信息,存储到nameidata的path域,同时把最后解析出来路径分量文件名(就是要打开的文件),存储到nameidata的last域
- 根据父目录dentry信息,如果是已存在文件,就查询当前文件的dentry项;如果是新文件,那么就构造新的dentry,同时调用inode的操作create创建文件
1)构造nameidata结构体:
nameidata这个结构体,前四个字段,记录了当前目录path对象、文件名、根path对象、以及当前目录的索引节点。
struct nameidata {
struct path path;
struct qstr last;
struct path root;
struct inode *inode; /* path.dentry.d_inode */
unsigned int flags, state;
unsigned seq, m_seq, r_seq;
int last_type;
unsigned depth;
int total_link_count;
struct saved {
struct path link;
struct delayed_call done;
const char *name;
unsigned seq;
} *stack, internal[EMBEDDED_LEVELS];
struct filename *name;
struct nameidata *saved;
unsigned root_seq;
int dfd;
kuid_t dir_uid;
umode_t dir_mode;
} __randomize_layout;
static void __set_nameidata(struct nameidata *p, int dfd, struct filename *name)
{
struct nameidata *old = current->nameidata;
p->stack = p->internal;
p->depth = 0;
p->dfd = dfd;
p->name = name;
p->path.mnt = NULL;
p->path.dentry = NULL;
p->total_link_count = old ? old->total_link_count : 0;
p->saved = old;
current->nameidata = p;
}
2)path初始化
以下就是path初始化代码片段,最重要代码就是从current中获取fs_struct结构体,这样就得到当前进程工作目录的path对象(fs->pwd),也就是文件的父目录的path对象,进而就得到了dentry项和索引节点,然后把这些信息赋值给nameidata结构nd,供后续使用。
那current是什么?看内核代码可知,在X86环境下,current是个per-cpu变量,栈顶就是用户态进程结构task_struct;而在Arm环境中,这个结构放在寄存器sp0里,可以从寄存器快速获取。
static __always_inline struct task_struct *get_current(void)
{
return this_cpu_read_stable(current_task);
}
/* must be paired with terminate_walk() */
static const char *path_init(struct nameidata *nd, unsigned flags)
{
int error;
const char *s = nd->name->name;
......
/* Relative pathname -- get the starting-point it is relative to. */
if (nd->dfd == AT_FDCWD) {
if (flags & LOOKUP_RCU) {
struct fs_struct *fs = current->fs;
unsigned seq;
do {
seq = read_seqcount_begin(&fs->seq);
nd->path = fs->pwd;
nd->inode = nd->path.dentry->d_inode;
nd->seq = __read_seqcount_begin(&nd->path.dentry->d_seq);
} while (read_seqcount_retry(&fs->seq, seq));
} else {
get_fs_pwd(current->fs, &nd->path);
nd->inode = nd->path.dentry->d_inode;
}
}
......
}3)逐级路径分量解析
路径分量解析是整个打开文件的核心,代码逻辑非常复杂,涉及多个函数嵌套调用:link_path_walk(大循环)->walk_component(处理单个分量)->step_into(深入处理当前分量)->handle_mount(应对挂载点)->pick_link(处理软连接)等等。
但是,这个步骤的目标是清晰的,一共有两个:一个是要获得打开文件父目录的目录项detnry,围绕这个目标,路径解析要应对很多复杂情况,下面罗列一下:
- 路径中可能有.(上层目录)或..(上上层目录),需要进行Jump操作
- 路径中某个目录可能是另外一个文件系统挂载点,要跟踪这个挂载信息,切换文件系统
- 路径中某个分量可能是软链接symlink,需要跟踪这个链接到目标
为了理解整个过程,这里画了一个处理流程图,这是代码调用的大体流程,稍微简化了一点,实际代码中包含了很多判断逻辑更加复杂:

/*
* Name resolution.
* This is the basic name resolution function, turning a pathname into
* the final dentry. We expect 'base' to be positive and a directory.
*
* Returns 0 and nd will have valid dentry and mnt on success.
* Returns error and drops reference to input namei data on failure.
*/
static int link_path_walk(const char *name, struct nameidata *nd)
{
int depth = 0; // depth <= nd->depth
int err;
nd->last_type = LAST_ROOT;
nd->flags |= LOOKUP_PARENT;
while (*name=='/') // 去除前面的斜杠
name++;
/* 此处开始大循环,进行路径分量解析,代码叫path component. */
for(;;) {
struct user_namespace *mnt_userns;
const char *link;
u64 hash_len;
int type;
mnt_userns = mnt_user_ns(nd->path.mnt);
// 获取当前分量hash长度
hash_len = hash_name(nd->path.dentry, name);
// 检查是否有.或..,如果有要进行JUMP,记录到nd->state里
type = LAST_NORM;
if (name[0] == '.') switch (hashlen_len(hash_len)) {
case 2:
if (name[1] == '.') {
type = LAST_DOTDOT;
nd->state |= ND_JUMPED;
}
break;
case 1:
type = LAST_DOT;
}
......
nd->last.hash_len = hash_len;
nd->last.name = name;
nd->last_type = type;
name += hashlen_len(hash_len);
if (!*name) // 如果路径结束了,goto OK 进行解析
goto OK;
......
if (unlikely(!*name)) { // 已经是最后一个component了
OK:
/* pathname or trailing symlink, done */
if (!depth) {
nd->dir_uid = i_uid_into_mnt(mnt_userns, nd->inode);
nd->dir_mode = nd->inode->i_mode;
nd->flags &= ~LOOKUP_PARENT;
return 0;
}
/* last component of nested symlink */
name = nd->stack[--depth].name; // 记录文件名
link = walk_component(nd, 0); // 解析当前路径分量,获取dentry信息
} else {
/* not the last component */
link = walk_component(nd, WALK_MORE); // 不是最后一个component
}
......
}
}
static const char *walk_component(struct nameidata *nd, int flags)
{
struct dentry *dentry;
struct inode *inode;
unsigned seq;
/*
* "." and ".." are special - ".." especially so because it has
* to be able to know about the current root directory and
* parent relationships.
*/
if (unlikely(nd->last_type != LAST_NORM)) {
if (!(flags & WALK_MORE) && nd->depth)
put_link(nd);
return handle_dots(nd, nd->last_type);
}
dentry = lookup_fast(nd, &inode, &seq);
......
if (!(flags & WALK_MORE) && nd->depth)
put_link(nd);
return step_into(nd, flags, dentry, inode, seq);
}4)搜索(或构造)打开文件的dentry
经过第3步的路径解析,已经获取了父目录的的dentry项,有了父目录的dentry项,是不是就可以搜索要打开文件的dentry了。经过前面几个步骤的铺垫,这才刚刚进入正题.
接下来就是调用open_last_lookups()函数,搜索打开文件的Dentry,如果未搜索到,将会构造一个dentry项,一起来看下代码:
- open_last_lookups()函数中,会先给nameidata结构path域中dentry项,对应的inode加锁,然后调用lookup_open()函数
- lookup_open()函数中,使用传入的path域,作为文件的父dentry,last域作为文件名,调用d_lookup()函数,搜索文件的dentry
- 检查搜索结果,如果dentry不存在,使用d_alloc_parallel()构造一个dentry,然后调用父目录的dir_inode->i_op->create()创建文件,注意参数是父项inode,当前文件dentry。
static const char *open_last_lookups(struct nameidata *nd,
struct file *file, const struct open_flags *op)
{
struct dentry *dir = nd->path.dentry;
int open_flag = op->open_flag;
bool got_write = false;
unsigned seq;
struct inode *inode;
struct dentry *dentry;
const char *res;
nd->flags |= op->intent;
......
if (open_flag & O_CREAT)
inode_lock(dir->d_inode);
else
inode_lock_shared(dir->d_inode);
dentry = lookup_open(nd, file, op, got_write);
if (!IS_ERR(dentry) && (file->f_mode & FMODE_CREATED))
fsnotify_create(dir->d_inode, dentry);
if (open_flag & O_CREAT)
inode_unlock(dir->d_inode);
else
inode_unlock_shared(dir->d_inode);
if (got_write)
mnt_drop_write(nd->path.mnt);
......
return res;
}
/*
* Look up and maybe create and open the last component.
*
* Must be called with parent locked (exclusive in O_CREAT case).
*
* Returns 0 on success, that is, if
* the file was successfully atomically created (if necessary) and opened, or
* the file was not completely opened at this time, though lookups and
* creations were performed.
* These case are distinguished by presence of FMODE_OPENED on file->f_mode.
* In the latter case dentry returned in @path might be negative if O_CREAT
* hadn't been specified.
*
* An error code is returned on failure.
*/
static struct dentry *lookup_open(struct nameidata *nd, struct file *file,
const struct open_flags *op,
bool got_write)
{
struct user_namespace *mnt_userns;
struct dentry *dir = nd->path.dentry;
struct inode *dir_inode = dir->d_inode;
int open_flag = op->open_flag;
struct dentry *dentry;
int error, create_error = 0;
umode_t mode = op->mode;
DECLARE_WAIT_QUEUE_HEAD_ONSTACK(wq);
if (unlikely(IS_DEADDIR(dir_inode)))
return ERR_PTR(-ENOENT);
file->f_mode &= ~FMODE_CREATED;
dentry = d_lookup(dir, &nd->last);
for (;;) {
if (!dentry) {
dentry = d_alloc_parallel(dir, &nd->last, &wq);
}
......
}
......
/* Negative dentry, just create the file */
if (!dentry->d_inode && (open_flag & O_CREAT)) {
file->f_mode |= FMODE_CREATED;
......
error = dir_inode->i_op->create(mnt_userns, dir_inode, dentry,
mode, open_flag & O_EXCL);
if (error)
goto out_dput;
}
if (unlikely(create_error) && !dentry->d_inode) {
error = create_error;
goto out_dput;
}
return dentry;
......
}5.打开文件,获取file对象
经过上面充分的准备,终于来到了最后一个操作:打开文件。
这一步有几个函数调用:do_open() -> vfs_open() -> do_dentry_open(),其中最重要操作就在do_dentry_open中,这个函数最终调用file对象操作表中的open()函数打开文件。如果分步来看的话,一共以下几个步骤:
- 给文件对象file的属性赋值:f_inode 、f_mapping、f_wb_err、f_sb_err等
- 将inode的i_fop域赋值给file对象的f_op域,那i_fop域的值是哪来的呢?这个值是,文件系统注册到VFS时,携带给inode的操作表,里面包含了打开文件的open()函数。
- 调用file对象的f_op->open()函数打开文件
- 给文件对象file的属性赋值:f_mode、f_write_hint 、f_ra等
注意:关联fd和file对象,已经在第2步调用处介绍,此部分不再赘述
/*
* Handle the last step of open()
*/
static int do_open(struct nameidata *nd,
struct file *file, const struct open_flags *op)
{
......
if (!error && !(file->f_mode & FMODE_OPENED))
error = vfs_open(&nd->path, file);
......
return error;
}
/**
* vfs_open - open the file at the given path
* @path: path to open
* @file: newly allocated file with f_flag initialized
* @cred: credentials to use
*/
int vfs_open(const struct path *path, struct file *file)
{
file->f_path = *path;
return do_dentry_open(file, d_backing_inode(path->dentry), NULL);
}
static int do_dentry_open(struct file *f,
struct inode *inode,
int (*open)(struct inode *, struct file *))
{
static const struct file_operations empty_fops = {};
int error;
path_get(&f->f_path);
f->f_inode = inode;
f->f_mapping = inode->i_mapping;
f->f_wb_err = filemap_sample_wb_err(f->f_mapping);
f->f_sb_err = file_sample_sb_err(f);
......
f->f_op = fops_get(inode->i_fop);
/* normally all 3 are set; ->open() can clear them if needed */
f->f_mode |= FMODE_LSEEK | FMODE_PREAD | FMODE_PWRITE;
if (!open)
open = f->f_op->open;
if (open) {
error = open(inode, f);
if (error)
goto cleanup_all;
}
f->f_mode |= FMODE_OPENED;
if ((f->f_mode & (FMODE_READ | FMODE_WRITE)) == FMODE_READ)
i_readcount_inc(inode);
if ((f->f_mode & FMODE_READ) &&
likely(f->f_op->read || f->f_op->read_iter))
f->f_mode |= FMODE_CAN_READ;
if ((f->f_mode & FMODE_WRITE) &&
likely(f->f_op->write || f->f_op->write_iter))
f->f_mode |= FMODE_CAN_WRITE;
f->f_write_hint = WRITE_LIFE_NOT_SET;
f->f_flags &= ~(O_CREAT | O_EXCL | O_NOCTTY | O_TRUNC);
file_ra_state_init(&f->f_ra, f->f_mapping->host->i_mapping);
.....
return error;
}三、总结
这一部分总结一下打开文件的几个步骤:生成文件描述符、构造文件对象、路径分量解析、最终打开文件。产生联系的重要数据结构有:
- struct file
- struct path
- struct task_struct
- struct fs_struct
- struct nameidata
- struct dentry
- struct inode
接下来回答一下开头提出的问题:
- 打开文件的内核入口在哪里?–do_sys_open()函数
- 打开文件时,如何知道当前属于哪个文件系统呢?–根据getcurrent()函数,从进程的task_struct结构的fs域,通过fs->pwd获取
- 如果文件已存在,那又如何获取目录项dentry和索引节点inode呢?–在路径解析步骤,通过传递父dentry和文件名搜索出文件的dentry,进而得到inode
- 文件对象file是怎么构造的?–通过函数alloc_empty_file()构造,然后不断填充属性信息
- 文件描述符是怎么产生的,又是如何跟file对象关联起来?–文件描述符fd,就是位图中为0的位置,通过fdtable与fd关联
上一篇:Linux文件系统数据结构详解:文件对象struct file
源码:5.16.7
《011 Linux一次文件打开过程open()》有2个想法