上一篇介绍了ext2注册文件系统注册的流程,其中提到在注册文件系统时,给VFS传递了file_system_type结构体,在这个结构体中,包含了挂载函数指针ext2_mount(),用于挂载的回调操作。
在ext2_mount()函数实现中,调用了VFS的mount_bdev()来挂载块设备,这个mount_bdev()函数最后一个参数,是一个函数指针,VFS使用此函数完成超级块的构造和填充,而超级块是文件系统核心数据结构,它的构造是构建文件系统主要流程,本文就重点梳理一下超级块的构造,以下是mount_bdev()函数原型:
dentry *mount_bdev(struct file_system_type *fs_type,
int flags, const char *dev_name, void *data,
int (*fill_super)(struct super_block *, void *, int));一、先说数据结构
在说超级块的构造之前,有必要说一下超级块数据结构,前面章节介绍过,一般情况下,超级块结构有如下三种形态:
- 磁盘上超级块结构,持久化结构(struct ext2_super_block)
- 内存中缓存的超级块结构体(struct ext2_sb_info)
- 文件系统挂载后,VFS使用的超级块(struct super_block)
ext2文件系统也不例外,也存在三种形态的超级块,并且这三种超级块类型,通过字段可以关联起来,这是文件系统实现的常规做法。
首先,VFS超级块super_block通过s_fs_info域可以链接到内存超级块,在内存超级块的结构中s_es域链接到持久化的超级块,这样就把三个结构体串联起来。
在Linux系统中,文件系统数据流转过程,传递的都是VFS的超级块,通过这个超级块就可以获取其他两个形态的结构,非常的方便。
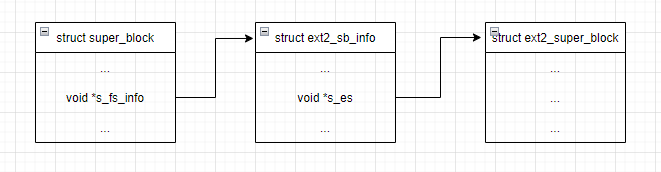
VFS使用的超级块,是所有文件系统公用的,前面章节已经介绍过,所以本篇博客只介绍ext2特有的两个结构,持久化结构和内存中结构。
1.持久化超级块:ext2_super_block
以下代码是ext2的磁盘超级块结构,展示了超级块在磁盘上的存储格式,包含了整个ext2文件系统的信息:inode数量、block数量、空闲的block数量、空闲的inode数量、块组信息、碎片信息、第一个数据block、group信息等
/*
* Structure of the super block
*/
struct ext2_super_block {
__le32 s_inodes_count; /* Inodes count */
__le32 s_blocks_count; /* Blocks count */
__le32 s_r_blocks_count; /* Reserved blocks count */
__le32 s_free_blocks_count; /* Free blocks count */
__le32 s_free_inodes_count; /* Free inodes count */
__le32 s_first_data_block; /* First Data Block */
__le32 s_log_block_size; /* Block size */
__le32 s_log_frag_size; /* Fragment size */
__le32 s_blocks_per_group; /* # Blocks per group */
__le32 s_frags_per_group; /* # Fragments per group */
__le32 s_inodes_per_group; /* # Inodes per group */
__le32 s_mtime; /* Mount time */
__le32 s_wtime; /* Write time */
__le16 s_mnt_count; /* Mount count */
__le16 s_max_mnt_count; /* Maximal mount count */
__le16 s_magic; /* Magic signature */
__le16 s_state; /* File system state */
__le16 s_errors; /* Behaviour when detecting errors */
__le16 s_minor_rev_level; /* minor revision level */
__le32 s_lastcheck; /* time of last check */
__le32 s_checkinterval; /* max. time between checks */
__le32 s_creator_os; /* OS */
__le32 s_rev_level; /* Revision level */
__le16 s_def_resuid; /* Default uid for reserved blocks */
__le16 s_def_resgid; /* Default gid for reserved blocks */
/*
* These fields are for EXT2_DYNAMIC_REV superblocks only.
*
* Note: the difference between the compatible feature set and
* the incompatible feature set is that if there is a bit set
* in the incompatible feature set that the kernel doesn't
* know about, it should refuse to mount the filesystem.
*
* e2fsck's requirements are more strict; if it doesn't know
* about a feature in either the compatible or incompatible
* feature set, it must abort and not try to meddle with
* things it doesn't understand...
*/
__le32 s_first_ino; /* First non-reserved inode */
__le16 s_inode_size; /* size of inode structure */
__le16 s_block_group_nr; /* block group # of this superblock */
__le32 s_feature_compat; /* compatible feature set */
__le32 s_feature_incompat; /* incompatible feature set */
__le32 s_feature_ro_compat; /* readonly-compatible feature set */
__u8 s_uuid[16]; /* 128-bit uuid for volume */
char s_volume_name[16]; /* volume name */
char s_last_mounted[64]; /* directory where last mounted */
__le32 s_algorithm_usage_bitmap; /* For compression */
/*
* Performance hints. Directory preallocation should only
* happen if the EXT2_COMPAT_PREALLOC flag is on.
*/
__u8 s_prealloc_blocks; /* Nr of blocks to try to preallocate*/
__u8 s_prealloc_dir_blocks; /* Nr to preallocate for dirs */
__u16 s_padding1;
/*
* Journaling support valid if EXT3_FEATURE_COMPAT_HAS_JOURNAL set.
*/
__u8 s_journal_uuid[16]; /* uuid of journal superblock */
__u32 s_journal_inum; /* inode number of journal file */
__u32 s_journal_dev; /* device number of journal file */
__u32 s_last_orphan; /* start of list of inodes to delete */
__u32 s_hash_seed[4]; /* HTREE hash seed */
__u8 s_def_hash_version; /* Default hash version to use */
__u8 s_reserved_char_pad;
__u16 s_reserved_word_pad;
__le32 s_default_mount_opts;
__le32 s_first_meta_bg; /* First metablock block group */
__u32 s_reserved[190]; /* Padding to the end of the block */
};2.内存超级块:ext2_sb_info
以下是内存中超级块的结构,与磁盘超级块类似,包含了inode、block块信息、计数器等等。
/*
* second extended-fs super-block data in memory
*/
struct ext2_sb_info {
unsigned long s_frag_size; /* Size of a fragment in bytes */
unsigned long s_frags_per_block;/* Number of fragments per block */
unsigned long s_inodes_per_block;/* Number of inodes per block */
unsigned long s_frags_per_group;/* Number of fragments in a group */
unsigned long s_blocks_per_group;/* Number of blocks in a group */
unsigned long s_inodes_per_group;/* Number of inodes in a group */
unsigned long s_itb_per_group; /* Number of inode table blocks per group */
unsigned long s_gdb_count; /* Number of group descriptor blocks */
unsigned long s_desc_per_block; /* Number of group descriptors per block */
unsigned long s_groups_count; /* Number of groups in the fs */
unsigned long s_overhead_last; /* Last calculated overhead */
unsigned long s_blocks_last; /* Last seen block count */
struct buffer_head * s_sbh; /* Buffer containing the super block */
struct ext2_super_block * s_es; /* Pointer to the super block in the buffer */
struct buffer_head ** s_group_desc;
unsigned long s_mount_opt;
unsigned long s_sb_block;
kuid_t s_resuid;
kgid_t s_resgid;
unsigned short s_mount_state;
unsigned short s_pad;
int s_addr_per_block_bits;
int s_desc_per_block_bits;
int s_inode_size;
int s_first_ino;
spinlock_t s_next_gen_lock;
u32 s_next_generation;
unsigned long s_dir_count;
u8 *s_debts;
struct percpu_counter s_freeblocks_counter;
struct percpu_counter s_freeinodes_counter;
struct percpu_counter s_dirs_counter;
struct blockgroup_lock *s_blockgroup_lock;
/* root of the per fs reservation window tree */
spinlock_t s_rsv_window_lock;
struct rb_root s_rsv_window_root;
struct ext2_reserve_window_node s_rsv_window_head;
/*
* s_lock protects against concurrent modifications of s_mount_state,
* s_blocks_last, s_overhead_last and the content of superblock's
* buffer pointed to by sbi->s_es.
*
* Note: It is used in ext2_show_options() to provide a consistent view
* of the mount options.
*/
spinlock_t s_lock;
struct mb_cache *s_ea_block_cache;
struct dax_device *s_daxdev;
};二、构造(填充)超级块
文章开头已经说明,在挂载ext2文件系统时,VFS将会回调ext2_mount函数,在ext2_mount()函数中,调用VFS的mount_bdev()函数,携带了填充超级块的函数指针ext2_fill_super,VFS挂载后将会使用此函数构造超级块,函数指针原型如下:
/*
* param1:VFS超级块对象
* param2:mount挂载时,携带的选项数据
* param3:未使用
*/
int ext2_fill_super(struct super_block *sb, void *data, int silent)这个填充函数ext2_fill_super(),主要实现了几个功能:填充了VFS的超级块sb、构造了内存超级块sbi、构造持久化超级块es,具体流程见下面的分解动作:
1.获取超级块起始位置*
下面的代码是解析mount选项(get_sb_block),确认是否携带了sb=xxx参数,这个参数是指定超级块位置,单位是K。如果sb=1,表示从1K开始是超级块位置,sb的默认值就是1,也就是第二个1024位置。第一个1024位置是磁盘引导块,文件系统不使用。
unsigned long sb_block = get_sb_block(&data);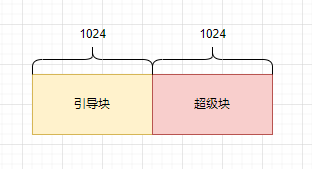
2.读取磁盘超级块***
调用sb_bread()函数,从磁盘上读取超级块,一共传递了三个非常重要的参数:
- sb->s_bdev:块设备信息,这是挂载操作指定的块
- block:块号,也就是起始块,超级块默认是1
- sb->s_blocksize:块大小,默认是1024字节
读取磁盘超级块到内存之后,在首地址加了一个offset,其实offset默认值为0,如果超级块在特殊偏移位置,可以使用offset。
然后,把超级块内存首地址给了sbi的s_es域,同时获取魔术数给VFS的超级块。
if (!(bh = sb_bread(sb, logic_sb_block))) {
ext2_msg(sb, KERN_ERR, "error: unable to read superblock");
goto failed_sbi;
}
/*
* Note: s_es must be initialized as soon as possible because
* some ext2 macro-instructions depend on its value
*/
es = (struct ext2_super_block *) (((char *)bh->b_data) + offset);
sbi->s_es = es;
sb->s_magic = le16_to_cpu(es->s_magic);
/*
* Read a block from bdev
*/
static inline struct buffer_head *
sb_bread(struct super_block *sb, sector_t block)
{
return __bread_gfp(sb->s_bdev, block, sb->s_blocksize, __GFP_MOVABLE);
}3.初始化内存和VFS超级块信息1
这一部分主要是根据磁盘超级块信息,来初始化内存超级块,主要内容包括:
- 各种挂载选项(es->s_default_mount_opts)
- 块用户ID和组ID(es->s_def_resuid,es->s_def_resgid)
- 检查s_rev_level、features、只读属性
这一部分代码较为简单,这里不做详细展开。
4.再次读取超级块
为什么要重新读取超级块呢,如果逻辑块大小与之前计算的不一致,需要重新计算超级块块号和偏移量,然后调用sb_bread()重新读取,整体逻辑与第2步中类似,此处不做过多赘述。
blocksize = BLOCK_SIZE << le32_to_cpu(sbi->s_es->s_log_block_size);
/* If the blocksize doesn't match, re-read the thing.. */
if (sb->s_blocksize != blocksize) {
brelse(bh);
if (!sb_set_blocksize(sb, blocksize)) {
ext2_msg(sb, KERN_ERR,
"error: bad blocksize %d", blocksize);
goto failed_sbi;
}
logic_sb_block = (sb_block*BLOCK_SIZE) / blocksize;
offset = (sb_block*BLOCK_SIZE) % blocksize;
bh = sb_bread(sb, logic_sb_block);
if(!bh) {
ext2_msg(sb, KERN_ERR, "error: couldn't read"
"superblock on 2nd try");
goto failed_sbi;
}
es = (struct ext2_super_block *) (((char *)bh->b_data) + offset);
sbi->s_es = es;
if (es->s_magic != cpu_to_le16(EXT2_SUPER_MAGIC)) {
ext2_msg(sb, KERN_ERR, "error: magic mismatch");
goto failed_mount;
}
}5.初始化内存和VFS超级块信息2
第4步获取准确的逻辑块大小,读取了准确的超级块信息,接下来把这些信息赋值给内存超级块和VFS超级块:
- sb->s_maxbytes:计算ext2支持最大文件大小
- sb->s_max_links:最大支持的链接数:32000
- sbi->s_inode_size:单个Inode结构大小
- sbi->s_first_ino:第一个使用的inode编号(非系统保留的inode)
- sbi->s_frag_size:单个碎片大小,最小默认为1024字节
- sbi->s_frags_per_block:使用逻辑块大小除以碎片大小
- sbi->s_blocks_per_group:每个块组的块数
- sbi->s_frags_per_group:每个块组的碎片数
- sbi->s_inodes_per_group:每个块组的inode数
- sbi->s_inodes_per_block:每个逻辑块的inode数,逻辑块大小除以inode大小
- sbi->s_itb_per_group:每个块组inode表块数
- sbi->s_desc_per_block:每个块的组描述符数,逻辑块大小除以组描述符大小
- sbi->s_sbh:磁盘超级块首地址
- sbi->s_mount_state:就是磁盘超级块里的文件系统状态es->s_state
- sbi->s_addr_per_block_bits:
- sbi->s_desc_per_block_bits:
sb->s_maxbytes = ext2_max_size(sb->s_blocksize_bits);
sb->s_max_links = EXT2_LINK_MAX;
sb->s_time_min = S32_MIN;
sb->s_time_max = S32_MAX;
if (le32_to_cpu(es->s_rev_level) == EXT2_GOOD_OLD_REV) {
sbi->s_inode_size = EXT2_GOOD_OLD_INODE_SIZE;
sbi->s_first_ino = EXT2_GOOD_OLD_FIRST_INO;
} else {
sbi->s_inode_size = le16_to_cpu(es->s_inode_size);
sbi->s_first_ino = le32_to_cpu(es->s_first_ino);
if ((sbi->s_inode_size < EXT2_GOOD_OLD_INODE_SIZE) ||
!is_power_of_2(sbi->s_inode_size) ||
(sbi->s_inode_size > blocksize)) {
ext2_msg(sb, KERN_ERR,
"error: unsupported inode size: %d",
sbi->s_inode_size);
goto failed_mount;
}
}
sbi->s_frag_size = EXT2_MIN_FRAG_SIZE <<
le32_to_cpu(es->s_log_frag_size);
if (sbi->s_frag_size == 0)
goto cantfind_ext2;
sbi->s_frags_per_block = sb->s_blocksize / sbi->s_frag_size;
sbi->s_blocks_per_group = le32_to_cpu(es->s_blocks_per_group);
sbi->s_frags_per_group = le32_to_cpu(es->s_frags_per_group);
sbi->s_inodes_per_group = le32_to_cpu(es->s_inodes_per_group);
sbi->s_inodes_per_block = sb->s_blocksize / EXT2_INODE_SIZE(sb);
if (sbi->s_inodes_per_block == 0 || sbi->s_inodes_per_group == 0)
goto cantfind_ext2;
sbi->s_itb_per_group = sbi->s_inodes_per_group /
sbi->s_inodes_per_block;
sbi->s_desc_per_block = sb->s_blocksize /
sizeof (struct ext2_group_desc);
sbi->s_sbh = bh;
sbi->s_mount_state = le16_to_cpu(es->s_state);
sbi->s_addr_per_block_bits =
ilog2 (EXT2_ADDR_PER_BLOCK(sb));
sbi->s_desc_per_block_bits =
ilog2 (EXT2_DESC_PER_BLOCK(sb));6.初始化内存和VFS超级块信息3
接下来继续初始化内存超级块和VFS超级块。
- sbi->s_groups_count:逻辑块组描述符数量
- sbi->s_blockgroup_lock:初始化所有块组锁
- sbi->s_debts:
- sbi->s_group_desc[i]:从设备上读取块组描述符
- sbi->s_gdb_count:
- sbi->s_freeblocks_counter:计数器初始化
- sb->s_op:超级块操作表
- sb->s_export_op:跟NFS交互的操作表
- sb->s_xattr:Xattr操作表
- sb->dq_op:磁盘配额特性操作表
- sb->s_qcop:磁盘配额特性控制操作表
- sb->s_quota_types:配额类型
sbi->s_groups_count = ((le32_to_cpu(es->s_blocks_count) -
le32_to_cpu(es->s_first_data_block) - 1)
/ EXT2_BLOCKS_PER_GROUP(sb)) + 1;
db_count = (sbi->s_groups_count + EXT2_DESC_PER_BLOCK(sb) - 1) /
EXT2_DESC_PER_BLOCK(sb);
sbi->s_group_desc = kmalloc_array(db_count,
sizeof(struct buffer_head *),
GFP_KERNEL);
if (sbi->s_group_desc == NULL) {
ret = -ENOMEM;
ext2_msg(sb, KERN_ERR, "error: not enough memory");
goto failed_mount;
}
bgl_lock_init(sbi->s_blockgroup_lock);
sbi->s_debts = kcalloc(sbi->s_groups_count, sizeof(*sbi->s_debts), GFP_KERNEL);
if (!sbi->s_debts) {
ret = -ENOMEM;
ext2_msg(sb, KERN_ERR, "error: not enough memory");
goto failed_mount_group_desc;
}
for (i = 0; i < db_count; i++) {
block = descriptor_loc(sb, logic_sb_block, i);
sbi->s_group_desc[i] = sb_bread(sb, block);
if (!sbi->s_group_desc[i]) {
for (j = 0; j < i; j++)
brelse (sbi->s_group_desc[j]);
ext2_msg(sb, KERN_ERR,
"error: unable to read group descriptors");
goto failed_mount_group_desc;
}
}
if (!ext2_check_descriptors (sb)) {
ext2_msg(sb, KERN_ERR, "group descriptors corrupted");
goto failed_mount2;
}
sbi->s_gdb_count = db_count;
get_random_bytes(&sbi->s_next_generation, sizeof(u32));
spin_lock_init(&sbi->s_next_gen_lock);
/* per filesystem reservation list head & lock */
spin_lock_init(&sbi->s_rsv_window_lock);
sbi->s_rsv_window_root = RB_ROOT;
/*
* Add a single, static dummy reservation to the start of the
* reservation window list --- it gives us a placeholder for
* append-at-start-of-list which makes the allocation logic
* _much_ simpler.
*/
sbi->s_rsv_window_head.rsv_start = EXT2_RESERVE_WINDOW_NOT_ALLOCATED;
sbi->s_rsv_window_head.rsv_end = EXT2_RESERVE_WINDOW_NOT_ALLOCATED;
sbi->s_rsv_window_head.rsv_alloc_hit = 0;
sbi->s_rsv_window_head.rsv_goal_size = 0;
ext2_rsv_window_add(sb, &sbi->s_rsv_window_head);
err = percpu_counter_init(&sbi->s_freeblocks_counter,
ext2_count_free_blocks(sb), GFP_KERNEL);
/*
* set up enough so that it can read an inode
*/
sb->s_op = &ext2_sops;
sb->s_export_op = &ext2_export_ops;
sb->s_xattr = ext2_xattr_handlers;
#ifdef CONFIG_QUOTA
sb->dq_op = &dquot_operations;
sb->s_qcop = &ext2_quotactl_ops;
sb->s_quota_types = QTYPE_MASK_USR | QTYPE_MASK_GRP;
#endif7.构造根inode
跟超级块类似,ext2文件系统的索引节点(inode)也有三种形态:
- 磁盘上持久化的inode:struct ext2_inode
- 内存中的inode:struct ext2_inode_info
- VFS使用的inode:struct inode
本文虽然是讲述超级块填充,因为超级块结构中s_root指向根dentry,所以需要创建根dentry,而dentry结构d_inode域指向索引节点,所以也就需要构造出根inode,然后填充到根dentry中。
构造根inode过程与构造超级块类似,需要根据根inode编号(编号是2),从磁盘上读取inode信息,然后填充到内存形态的inode和VFS使用inode。
主要涉及的函数有:ext2_iget() -> ext2_get_inode(),其中ext2_get_inode负责从设备上读取inode,ext2_iget负责填充到内存inode和VFS使用的inode。
root = ext2_iget(sb, EXT2_ROOT_INO);
if (IS_ERR(root)) {
ret = PTR_ERR(root);
goto failed_mount3;
}1)从磁盘读取inode
从磁盘读取inode的关键是知道块号,那如何计算块号呢?
- 首先根据inode编号,计算出inode所属的块组:(ino – 1) / EXT2_INODES_PER_GROUP(sb)
- 根据块组查找到块组描述符,这样就得到了inode_table的首地址
- 然后再计算具体的偏移量:就是取模的零头*一个inode大小
- 那块号就是,inode_table首地址
- 调用sb_bread()函数读取块信息
- 最终得到inode的首地址:bh->b_data + 偏移量
static struct ext2_inode *ext2_get_inode(struct super_block *sb, ino_t ino,
struct buffer_head **p)
{
struct buffer_head * bh;
unsigned long block_group;
unsigned long block;
unsigned long offset;
struct ext2_group_desc * gdp;
......
block_group = (ino - 1) / EXT2_INODES_PER_GROUP(sb);
gdp = ext2_get_group_desc(sb, block_group, NULL);
if (!gdp)
goto Egdp;
/*
* Figure out the offset within the block group inode table
*/
offset = ((ino - 1) % EXT2_INODES_PER_GROUP(sb)) * EXT2_INODE_SIZE(sb);
block = le32_to_cpu(gdp->bg_inode_table) +
(offset >> EXT2_BLOCK_SIZE_BITS(sb));
if (!(bh = sb_bread(sb, block)))
goto Eio;
*p = bh;
offset &= (EXT2_BLOCK_SIZE(sb) - 1);
return (struct ext2_inode *) (bh->b_data + offset);
......
}2)初始化内存中和VFS使用的inode信息
在ext2_iget()函数中,利用从磁盘读取的inode信息,完成了内存中Inode和VFS使用的Inode初始化:
- raw_inode:磁盘上inode(struct ext2_inode)
- ei:内存中inode(struct ext2_inode_info)
- inode:VFS使用的Inode(struct inode)
详细的处理逻辑见下方代码,代码逻辑比较简单,在此不做赘述。只说明一点,类似le16_to_cpu这种宏,是将磁盘上小端转换成CPU要求的,如果CPU要求小端序,将不做处理,如果CPU是大端序,将会从端转换成大端。
struct inode *ext2_iget (struct super_block *sb, unsigned long ino)
{
......
raw_inode = ext2_get_inode(inode->i_sb, ino, &bh);
if (IS_ERR(raw_inode)) {
ret = PTR_ERR(raw_inode);
goto bad_inode;
}
inode->i_mode = le16_to_cpu(raw_inode->i_mode);
i_uid = (uid_t)le16_to_cpu(raw_inode->i_uid_low);
i_gid = (gid_t)le16_to_cpu(raw_inode->i_gid_low);
if (!(test_opt (inode->i_sb, NO_UID32))) {
i_uid |= le16_to_cpu(raw_inode->i_uid_high) << 16;
i_gid |= le16_to_cpu(raw_inode->i_gid_high) << 16;
}
i_uid_write(inode, i_uid);
i_gid_write(inode, i_gid);
set_nlink(inode, le16_to_cpu(raw_inode->i_links_count));
inode->i_size = le32_to_cpu(raw_inode->i_size);
inode->i_atime.tv_sec = (signed)le32_to_cpu(raw_inode->i_atime);
inode->i_ctime.tv_sec = (signed)le32_to_cpu(raw_inode->i_ctime);
inode->i_mtime.tv_sec = (signed)le32_to_cpu(raw_inode->i_mtime);
inode->i_atime.tv_nsec = inode->i_mtime.tv_nsec = inode->i_ctime.tv_nsec = 0;
ei->i_dtime = le32_to_cpu(raw_inode->i_dtime);
......
inode->i_blocks = le32_to_cpu(raw_inode->i_blocks);
ei->i_flags = le32_to_cpu(raw_inode->i_flags);
ext2_set_inode_flags(inode);
ei->i_faddr = le32_to_cpu(raw_inode->i_faddr);
ei->i_frag_no = raw_inode->i_frag;
ei->i_frag_size = raw_inode->i_fsize;
ei->i_file_acl = le32_to_cpu(raw_inode->i_file_acl);
ei->i_dir_acl = 0;
if (ei->i_file_acl &&
!ext2_data_block_valid(EXT2_SB(sb), ei->i_file_acl, 1)) {
ext2_error(sb, "ext2_iget", "bad extended attribute block %u",
ei->i_file_acl);
ret = -EFSCORRUPTED;
goto bad_inode;
}
if (S_ISREG(inode->i_mode))
inode->i_size |= ((__u64)le32_to_cpu(raw_inode->i_size_high)) << 32;
else
ei->i_dir_acl = le32_to_cpu(raw_inode->i_dir_acl);
if (i_size_read(inode) < 0) {
ret = -EFSCORRUPTED;
goto bad_inode;
}
ei->i_dtime = 0;
inode->i_generation = le32_to_cpu(raw_inode->i_generation);
ei->i_state = 0;
ei->i_block_group = (ino - 1) / EXT2_INODES_PER_GROUP(inode->i_sb);
ei->i_dir_start_lookup = 0;
/*
* NOTE! The in-memory inode i_data array is in little-endian order
* even on big-endian machines: we do NOT byteswap the block numbers!
*/
for (n = 0; n < EXT2_N_BLOCKS; n++)
ei->i_data[n] = raw_inode->i_block[n];
if (S_ISREG(inode->i_mode)) {
ext2_set_file_ops(inode);
} else if (S_ISDIR(inode->i_mode)) {
inode->i_op = &ext2_dir_inode_operations;
inode->i_fop = &ext2_dir_operations;
if (test_opt(inode->i_sb, NOBH))
inode->i_mapping->a_ops = &ext2_nobh_aops;
else
inode->i_mapping->a_ops = &ext2_aops;
} else if (S_ISLNK(inode->i_mode)) {
if (ext2_inode_is_fast_symlink(inode)) {
inode->i_link = (char *)ei->i_data;
inode->i_op = &ext2_fast_symlink_inode_operations;
nd_terminate_link(ei->i_data, inode->i_size,
sizeof(ei->i_data) - 1);
} else {
inode->i_op = &ext2_symlink_inode_operations;
inode_nohighmem(inode);
if (test_opt(inode->i_sb, NOBH))
inode->i_mapping->a_ops = &ext2_nobh_aops;
else
inode->i_mapping->a_ops = &ext2_aops;
}
} else {
inode->i_op = &ext2_special_inode_operations;
if (raw_inode->i_block[0])
init_special_inode(inode, inode->i_mode,
old_decode_dev(le32_to_cpu(raw_inode->i_block[0])));
else
init_special_inode(inode, inode->i_mode,
new_decode_dev(le32_to_cpu(raw_inode->i_block[1])));
}
brelse (bh);
unlock_new_inode(inode);
return inode;
bad_inode:
brelse(bh);
iget_failed(inode);
return ERR_PTR(ret);
}8.创建根dentry
首先dentry跟超级块和inode不一样,超级块和Inode都有实体的磁盘结构,而dentry是为了快速搜索inode,每次文件系统装载时,都要重新构造dentry,所以它只有内存结构,没有磁盘结构。以下代码展示如何创建根dentry,大体上分为如下几个步骤:
- 分配dentry缓存
- dentry结构中文件名初始化
- d_lock、d_flags 、d_parent初始化
- d_sb链接到超级块
- 初始化各个链表:d_hash、d_lru、d_subdirs、d_child
- 使用sb->s_d_op来初始化d_op
- 调用d_op->d_init函数来完成dentry初始化
sb->s_root = d_make_root(root);
if (!sb->s_root) {
ext2_msg(sb, KERN_ERR, "error: get root inode failed");
ret = -ENOMEM;
goto failed_mount3;
}
struct dentry *d_make_root(struct inode *root_inode)
{
struct dentry *res = NULL;
if (root_inode) {
res = d_alloc_anon(root_inode->i_sb);
if (res)
d_instantiate(res, root_inode);
else
iput(root_inode);
}
return res;
}
struct dentry *d_alloc_anon(struct super_block *sb)
{
/* 第二个参数为NULL,说明是根dentry */
return __d_alloc(sb, NULL);
}
static struct dentry *__d_alloc(struct super_block *sb, const struct qstr *name)
{
struct dentry *dentry;
char *dname;
int err;
/* 给dentry分配缓存 */
dentry = kmem_cache_alloc(dentry_cache, GFP_KERNEL);
if (!dentry)
return NULL;
/*
* We guarantee that the inline name is always NUL-terminated.
* This way the memcpy() done by the name switching in rename
* will still always have a NUL at the end, even if we might
* be overwriting an internal NUL character
*/
dentry->d_iname[DNAME_INLINE_LEN-1] = 0;
if (unlikely(!name)) {
/* 文件名为空,使用“/” */
name = &slash_name;
dname = dentry->d_iname;
} else if (name->len > DNAME_INLINE_LEN-1) {
size_t size = offsetof(struct external_name, name[1]);
struct external_name *p = kmalloc(size + name->len,
GFP_KERNEL_ACCOUNT |
__GFP_RECLAIMABLE);
if (!p) {
kmem_cache_free(dentry_cache, dentry);
return NULL;
}
atomic_set(&p->u.count, 1);
dname = p->name;
} else {
dname = dentry->d_iname;
}
dentry->d_name.len = name->len;
dentry->d_name.hash = name->hash;
memcpy(dname, name->name, name->len);
dname[name->len] = 0;
/* Make sure we always see the terminating NUL character */
smp_store_release(&dentry->d_name.name, dname); /* ^^^ */
dentry->d_lockref.count = 1;
dentry->d_flags = 0;
spin_lock_init(&dentry->d_lock);
seqcount_spinlock_init(&dentry->d_seq, &dentry->d_lock);
dentry->d_inode = NULL;
dentry->d_parent = dentry;
/* 链接到超级块 */
dentry->d_sb = sb;
dentry->d_op = NULL;
dentry->d_fsdata = NULL;
/* 初始化各个链表 */
INIT_HLIST_BL_NODE(&dentry->d_hash);
INIT_LIST_HEAD(&dentry->d_lru);
INIT_LIST_HEAD(&dentry->d_subdirs);
INIT_HLIST_NODE(&dentry->d_u.d_alias);
INIT_LIST_HEAD(&dentry->d_child);
/* 设置d_op,并调用d_init函数,完成初始化 */
d_set_d_op(dentry, dentry->d_sb->s_d_op);
if (dentry->d_op && dentry->d_op->d_init) {
err = dentry->d_op->d_init(dentry);
if (err) {
if (dname_external(dentry))
kfree(external_name(dentry));
kmem_cache_free(dentry_cache, dentry);
return NULL;
}
}
/* 目录项计数器增加1 */
this_cpu_inc(nr_dentry);
return dentry;
}
10.检查revision_level
如果修订级别revision_level大于EXT2_MAX_SUPP_REV,将当前文件系统设置成只读。
static int ext2_setup_super (struct super_block * sb,
struct ext2_super_block * es,
int read_only)
{
int res = 0;
struct ext2_sb_info *sbi = EXT2_SB(sb);
if (le32_to_cpu(es->s_rev_level) > EXT2_MAX_SUPP_REV) {
ext2_msg(sb, KERN_ERR,
"error: revision level too high, "
"forcing read-only mode");
res = SB_RDONLY;
}
if (read_only)
return res;
.....
return res;
}11.同步超级块到磁盘
终于到了超级块的最后一步,将缓存中的超级块信息,同步到的磁盘上。为了完成同步,分为下面三个步骤来执行:
- 重新计算可用的块数量,然后设置给es->s_free_blocks_count
- 重新计算可用的Inode数量,然后设置给es->s_free_inodes_count
- 获取当前时间到秒数,作为写入时间赋值给s_wtime
- 将磁盘超级块的s_sbh缓存域标志成脏块:mark_buffer_dirty(EXT2_SB(sb)->s_sbh)
- 将磁盘超级块的s_sbh缓存域同步到磁盘:sync_dirty_buffer(EXT2_SB(sb)->s_sbh)
static void ext2_write_super(struct super_block *sb)
{
if (!sb_rdonly(sb))
ext2_sync_fs(sb, 1);
}
void ext2_sync_super(struct super_block *sb, struct ext2_super_block *es,
int wait)
{
ext2_clear_super_error(sb);
spin_lock(&EXT2_SB(sb)->s_lock);
es->s_free_blocks_count = cpu_to_le32(ext2_count_free_blocks(sb));
es->s_free_inodes_count = cpu_to_le32(ext2_count_free_inodes(sb));
es->s_wtime = cpu_to_le32(ktime_get_real_seconds());
/* unlock before we do IO */
spin_unlock(&EXT2_SB(sb)->s_lock);
mark_buffer_dirty(EXT2_SB(sb)->s_sbh);
if (wait)
sync_dirty_buffer(EXT2_SB(sb)->s_sbh);
}三、总结
挂载ext2文件系统时,会回调注册时提供的ext2_mount()函数,此函数调用mount_bdev()来挂载块设备,此函数要求提供填充超级块函数,ext2代码提供了ext2_fill_super()函数,来实现超级块构造和填充。
超级块有三种形态,磁盘上超级块、内存中超级块和VFS使用的超级块,他们都需要构造和填充,主要步骤包括:
- 从磁盘上读取磁盘超级块
- 初始化内存和VFS使用的超级块
- 从磁盘上读取根inode信息
- 初始化内存和VFS使用的inode
- 创建根dentry
- 将填充好的超级块信息,同步到磁盘上
参考资料:
https://www.cnblogs.com/codetravel/p/4779430.html
《02 ext2如何构造超级块super_block》有一个想法